Akonadi
Table of Contents
This is the API documentation for the Akonadi server. If you are using Akonadi from within KDE, you almost certainly want the [client library documentation][client_libs_documentation]. This API reference is more useful to people implementing client libraries or working on the Akonadi server itself.
For additional information, see the Akonadi website.
Architecture
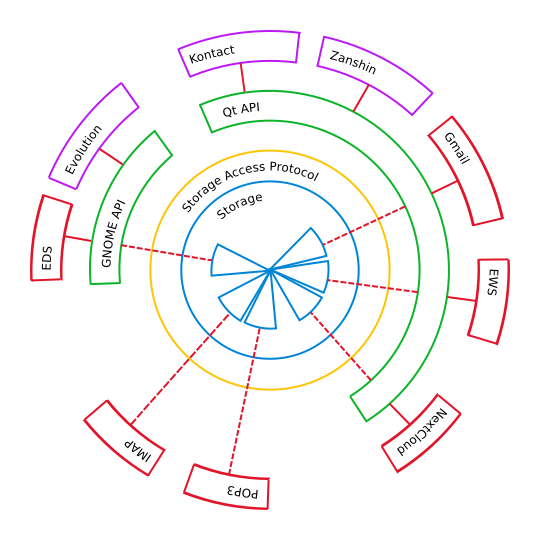
The Akonadi framework uses a client/server architecture. The Akonadi server has the following primary tasks:
- Abstract access to data from arbitrary sources, using toolkit-agnostic protocols and data formats
- Provide a data cache shared among several clients
- Provide change notifications and conflict detection
- Support offline change recording and change replay for remote data
Design Principles
The Akonadi architecture is based on the following four design principles:
- Functionality is spread over different processes. This separation has the big advantage that if one process crashes because of a programming error it doesn't affect the other components. That results in robustness of the whole system. A disadvantage might be that there is an additional overhead due to inter-process communication.
- Communication protocol is split into data and control channel. When doing communication between processes you have to differentiate between the type of data that is being transferred. For a large amount of data a high-performance protocol should be used and for control data a low-latency protocol. Matching both requirements in one protocol is mostly impossible and hard to achieve with currently available software.
- Separate logic from storage. By separating the logic from the storage, the storage can be used to store data of any type. In this case, the storage is a kind of service, which is available for other components of the system. The logic is located in separated components and so 3rd-party developers can extend the system by providing their own components.
- Keep communication asynchronous. To allow a non-blocking GUI, all the communication with the back-end and within the back-end itself must be asynchronous. You can easily provide a synchronous convenience for the application developer; the back-end, however, must communicate asynchronously.
Components
The Akonadi server itself consists of a number of components:
- The Akonadi control process (
akonadi_control). It is responsible for managing all other server components and Akonadi agents. - The Akonadi server process (
akonadiserver). The actual data access and caching server. - The Akonadi agent server (
akonadi_agent_server). Allows running of multiple Akonadi agents in one process. - The Akonadi agent launcher (
akonadi_agent_launcher). A helper process for running Akonadi agents. - The Akonadi control tool (
akonadictl). A tool to start/stop/restart the Akonadi server system and query its status. This is the only program of these listed here you should ever run manually. - The Akonadi protocol library (
libakonadiprotocolinternals), Contains protocol definitions and protocol parsing methods useful for client implementations.
The Akonadi server process
The Akonadi server process (akonadiserver) has the following tasks:
- Provide a transaction-safe data store.
- Provide operations to add/modify/delete items and collections in the local store, implementing the server side of the ASAP protocol.
- Cache management of cached remote contents.
- Manage virtual collections representing search results.
- Provide change notifications for all known Akonadi objects over D-Bus.
The Akonadi server control process
The Akondi control process (akonadi_control) has the following tasks:
- Manage and monitor the other server processes.
- Lifecycle management of agent instances using the various supported agent launch methods.
- Monitor agent instances and provide crash recovery.
- Provide D-Bus API to manage agents.
- Provide change notifications on agent types and agent instances.
Objects and Data Types
The Akonadi server operates on two basic object types, called items and collections. They are comparable to files and directories and are described in more detail in this section.
Akonadi Items
An item is a generic container for whatever you want to store in Akonadi (eg. mails, events, contacts, etc.). An item consists of some generic information (such as identifier, mimetype, change date, flags, etc.) and a set of data fields, the item parts. Items are independent of the type of stored data, the semantics of the actual content is only known on the client side.
Items Parts
Akonadi items can have one or more parts, e.g. an email message consists of the envelope, the body and possible one or more attachments. Item parts are identified by an identifier string. There are a few special pre-defined part identifiers (ALL, ENVELOPE, etc.), but in general the part identifiers are defined by the type specific extensions (ie. resource, serializer plugin, type specific client library).
Item Tags
Tags are self-contained entities stored in separate database table. A tag is a relation between multiple items. Tags can have different types (PLAIN, ...) and applications can define their own type to describe application-specific relations. Tags can also have attributes to store additional metadata about the relation the tag describes.
Payload Data Serialization
Item payload data is typically serialized in a standard format to ensure interoperability between different client library implementations. However, the Akonadi server does not enforce any format, payload data is handled as an opaque binary blob.
Collections
Collections are sets of items. Every item is stored in exactly one collection, this is sometimes also referred to as the "physical" storage location of the item. An item might also be visible in several other collections - so called "virtual collections" - which are defined as the result set of a search query.
Collections are organized hierarchically, i.e. a collection can have child collections, thus defining a collection tree.
Collections are uniquely identified by their identifier in contrast to their path, which is more robust with regard to renaming and moving.
Collection Properties
Every collection has a set of supported content types. These are the mimetypes of items the collection can contain. Example: A collection of a folder-less iCal file resource would only support "text/calendar" items, a folder on an IMAP server "message/rfc822" but also "inode/directory" if it can contain sub-folders.
There is a cache policy associated with every collection which defines how much of its content should be kept in the local cache and for how long.
Additionally, collections can contain an arbitrary set of attributes to represent various other collection properties such as ACLs, quotas or backend-specific data used for incremental synchronization. Evaluation of such attributes is the responsibility of client implementations, the Akonadi server does not interpret properties other than content types and cache policies.
Collection Tree
There is a single collection tree in Akonadi, consisting of several parts:
- A root node, id 0
- One or more top-level collections for each resource. Think of these as mount-points for the resource. The resources must put their items and sub-collections into their corresponding top-level collection.
- Resource-dependent sub-collections below the resource top-level collections. If the resource represents data that is organized in folders (e.g. an IMAP resource), it can create additional collections below its top-level collection. These have to be synched with the corresponding backend by the resource. Resources which represent folder-less data (e.g. an iCal file) don't need any sub-collections and put their items directly into the top-level collection.
- A top-level collection containing virtual collections.
Example:
+-+ resource-folder1 | +- sub-folder1 | +- sub-folder2 | ... +-+ resource-folder2 | ... | +-+ Searches +- search-folder1 +- search-folder2 ...
Object Identification
Unique Identifier
Every object stored in Akonadi (collections and items) has a unique identifier in the form of an integer value. This identifier cannot be changed in any way and will stay the same, regardless of any modifications to the referred object. A unique identifier will never be used twice and is globally unique, therefore it is possible to retrieve an item without knowing the collection it belongs to.
Remote Identifier
Every object can also have an optional so-called remote identifier. This is an identifier used by the corresponding resource to identify the object on its backend (e.g., a groupware server).
The remote identifier can be changed by the owning resource agent only.
Special case applies for Tags, where each tag can have multiple remote IDs. This fact is however opaque to resources as each resource is shown only the remote ID that it had provided when inserting the tag into Akonadi.
Global Identifier
Every item can has also so called GID, an identifier specific to the content (payload) of the item. The GID is extracted from the payload by client serializer when storing the item in Akonadi. For example, contacts have vCard "UID" field as their GID, emails can use value of "Message-Id" header.
Communication Protocols
For communication within the Akonadi server infrastructure and for communication with Akonadi clients, two communication technologies are used:
- D-Bus Used for management tasks and change notifications.
- ASAP (Akonadi Server Access Protocol), used for high-throughput data transfer. ASAP is based on the well-known IMAP protocol (RFC 3501) which has been proven it's ability to handle large quantities of data in practice already.
Interacting with Akonadi
There are various possibilities to interact with Akonadi.
Akonadi Client Libraries
Accessing the Akonadi server using the ASAP and D-Bus interfaces directly is cumbersome. Therefore you'd usually use a client library implementing the low-level protocol handling and providing convenient high-level APIs for Akonadi operations.
Akonadi Agents
Akonadi agents are processes which are controlled by the Akonadi server itself. Agents typically operate autonomously (ie. without much user interaction) on the objects handled by Akonadi, mostly by reacting to change notifications sent by the Akonadi server.
Agents can implement specialized interfaces to provide additional functionality. The most important ones are the so-called resource agents.
Resource agents are connectors that provide access to data from an external source, and replay local changes back to their corresponding backend.
Implementation Details
Data and Metadata Storage
The Akonadi server uses two mechanisms for data storage:
- A SQL databases for metadata and small payload data
- Plain files for large payload data
More details on the SQL database layout can be found here: akonadi_server_database.
The following SQL databases are supported by the Akonadi server:
- MySQL using the default QtSQL driver shipped with Qt
- Sqlite using the improved QtSQL driver shipped with the Akonadi server
- PostgreSQL using the default QtSQL driver shipped with Qt
For details on how to configure the various backends, see Akonadi::DataStore.
Documentation copyright © 1996-2025 The KDE developers.
Generated on Fri May 2 2025 11:53:10 by doxygen 1.13.2 written by Dimitri van Heesch, © 1997-2006
KDE's Doxygen guidelines are available online.